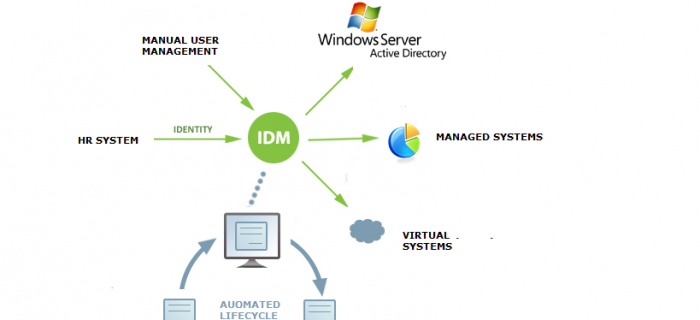
15 let partnerství a spolupráce
Vážení zákazníci a partneři, rádi bychom Vás pozvali na oslavu našich 15. narozenin. Těšíme se na na osobní setkání s Vámi, které se bude konat v prostorách Spojka Karlín ve středu 17.5.2023 od 9:30 do 13:00 hodin. Registrujte se níže. Rádi bychom Vám tedy představili základní harmonogram akce. Věříme, že i pro Vás bude toto […]
4. 4. 2023 • Aleš Roman