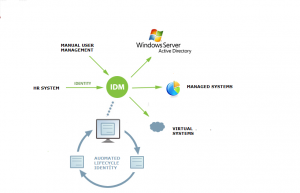
Jak vybrat Identity Manager (IDM)?
Stojíte před výběrem Identity Manageru (IDM)? Chcete vybrat nejlepší IDM? Tento článek dává doporučení, jak IDM zvolit. Na co si dát při výběru pozor. Jaké funkce jsou důležité a jaké ne. Nenajdete zde konkrétní volbu, jméno IDM, pak by článek rychle zastaral, protože vývoj jde velmi rychle dopředu. Každý potřebuje jinou skupinu vlastností. Každý produkt IDM […]
10. 4. 2019 • Lukáš Cirkva