Dynamické vytváření dokumentů
Při vytváření elektronických dokumentů často narazíte na situaci, kdy stále dokola vytváříte ty stejné dokumenty a pouze v nich měníte dokola ta stejná data. To Vás časem omrzí a začnete hledat způsob, jakým vaší práci zefektivnit a co nejvíce automatizovat. Ale jak na to? Můžeme zvolit některou z knihoven určených pro práci s konkrétním typem dokumentů nebo s dokumenty pracovat sami. Tento článek obsahuje informace, jak takovou situaci vyřešit bez jakékoliv knihovny pro práci s dokumenty a konkrétně s ukázkou na dokumentu OpenDocument Writer (.odt). Stejně tak je však možné pracovat i s dokumenty .xls, .doc atd.
Co je to vlastně .ODT dokument?
Dokumenty ODT jsou klasické ZIP archivy s příponou .odt. To znamená, že jako každý jiný .zip archiv je můžeme extrahovat. Jakmile tak uděláme, získáme adresář obsahující veškerá data dokumentu. Adresářová struktura je následující:
./Configurations2/ ./META-INF/ ./META-INF/manifest.xml ./Pictures/ ./Thumbnails/ ./content.xml ./manifest.rdf ./meta.xml ./mimetype ./settings.xml ./styles.xml
Celá adresářová struktura dokumentu je popsaná v oficiální specifikaci pro Open Document Format. Zde popíšu pouze nejzajímavější.
mimetype
Obsahuje informaci o MIME TYPE dokumentu. Z toho vyplývá, že na příponě samotného souboru dokumentu nezáleží, určující je obsah tohoto souboru.
/META-INF/manifest.xml
Obsahuje informace o všech souborech v adresářové struktuře dokumentu.
/Pictures
Obsahuje veškeré obrázky obsažené v dokumentu.
meta.xml
Meta informace dokumentu. Obsahuje informace jako jsou nadpis dokumentu, autor, datum vytvoření atd.
styles.xml
Obsahuje informace o stylech použitých v dokumentu.
content.xml
Pro nás asi nejdůležitější, obsahuje samotný obsah dokumentu. Veškeré změny v obsahu dokumentu, které chceme provést, je potřeba provést zde.
Práce s obsahem
V našem případě jsme potřebovali generovat .odt dokumenty, které se lišily pouze daty. Struktura dokumentů zůstává vždy stejná. Nebylo tedy potřebné generovat dynamicky vždy celý dokument, pracovat s novými styly atd., pouze s jeho části. Jak na to?
Nejdříve vytvoříme dokument, který bude sloužit jako šablona pro všechny další generované dokumenty. Taková zjednodušená šablona pro tento článek může vypadat například takto:
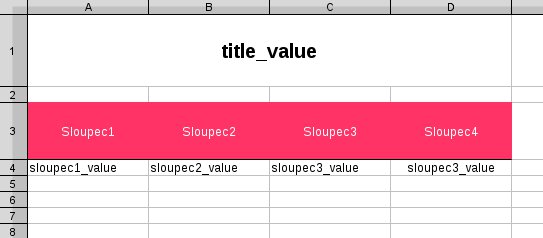
Šablonu uložíme standardně jako jakýkoliv jiný .odt dokument. Nyní dokument extrahujeme jako kdyby se jednalo o klasický .zip archiv. Vytvoří se nám adresář <nazev_dokumentu>_FILES s adresářovou strukturou uvedenou v úvodu tohoto článku. Otevřeme soubor content.xml. Obsah je podobný jazyku HTML. V obsahu si najdeme části, které budeme potřebovat dynamicky upravovat s každým novým dokumentem. V našem případě to je nadpis dokumentu:
<text:p>title_value</text:p>
a obsah tabulky, bez nadpisů jednotlivých sloupců. Jeden řádek tabulky odpovídá této struktuře:
<table:table-row table:style-name="ro2">
<table:table-cell office:value-type="string">
<text:p>sloupec1_value</text:p>
</table:table-cell>
<table:table-cell office:value-type="string">
<text:p>sloupec2_value</text:p>
</table:table-cell>
<table:table-cell office:value-type="string">
<text:p>sloupec3_value</text:p>
</table:table-cell>
<table:table-cell office:value-type="float" office:value="1">
<text:p>sloupec4_value</text:p>
</table:table-cell>
</table:table-row>
Z těchto ústřížků kódu si můžeme vytvořit šablony tak, že do dynamicky generovaných míst doplníme proměnné. Například takto:
Nadpis dokumentu:
<text:p>$document_title$</text:p>
Obsah dokumentu:
<table:table-row table:style-name="ro2">
<table:table-cell office:value-type="string">
<text:p>$table_column_1$</text:p>
</table:table-cell>
<table:table-cell office:value-type="string">
<text:p>$table_column_2$</text:p>
</table:table-cell>
<table:table-cell office:value-type="string">
<text:p>$table_column_3$</text:p>
</table:table-cell>
<table:table-cell office:value-type="float" office:value="1">
<text:p>$table_column_4$</text:p>
</table:table-cell>
</table:table-row>
V souboru content.xml je ještě potřeba doplnit na místo, kam se má vygenerovaná struktura vložit,nějaké označení. Do místa nového nadpisu například $title_insert$, nových řádků tabulky pak třeba $table_rows_insert$. Nyní stačí v libovolném programovacím jazyce vytvořit novou strukturu s nahrazenými proměnnými a vložit je do předpřipravené šablony souboru content.xml. Jelikož se jedná již jen o jednoduché nahrazení textu a zapsání do souboru, neuvádím zde konkrétní příklad. K novému content.xml již stačí jen přidat zbývající adresářovou strukturu původně extrahovaného dokumentu, zkomprimovat a přejmenovat na soubor s koncovkou .odt.
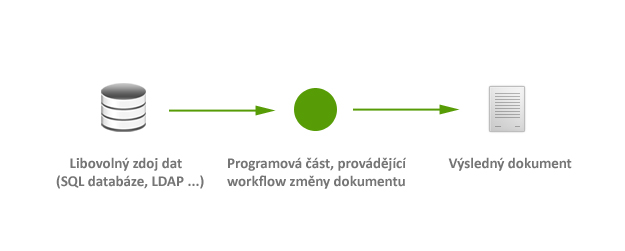
Workflow změny dokumentu
Celé workflow změny dokumentu by se dalo zapsat v jednoduchosti takto:
- vygenerování nových dat dle předpřipravených šablon částí dokumentu
- načtení obsahu šablony content.xml
- vložení nově vygenerovaných dat do souboru content.xml na požadovaná místa
- překopírování zbývající adresářové struktury dokumentu k novému content.xml
- komprimace celé adresářové struktury
- změna přípony vytvořeného archivu například na document.odt
- zaslání dokumentu uživateli
Závěr
V případě, že je vše vytvořeno správně, je výsledkem .odt dokument s požadovanými daty. Pokud Vás toto téma zaujalo nebo byste ocenili další informace, neváhejte mne kontaktovat na info@bcvsolutions.eu.