Nový lexer do Netbeans – barevný svět v hrsti
V posledních dnech jsem se zabýval vývojem drobného dárku pro naše vývojáře a vlastně všechny, kteří vyvíjí workflow pro Identity Management CzechIdM. Když workflow vyvíjíte, de facto píšete kód skriptovacího jazyka Beanshell do XML struktury. A jelikož vás vývojová prostředí Eclipse a Netbeans v takové situaci nechají na holičkách, celý text je černý a o chybě se dozvíte až při spuštění, rozhodl jsem se je malinko rozšířit a vnést do zdrojového kódu barvy… Ostatně, výsledek posuďte sami:
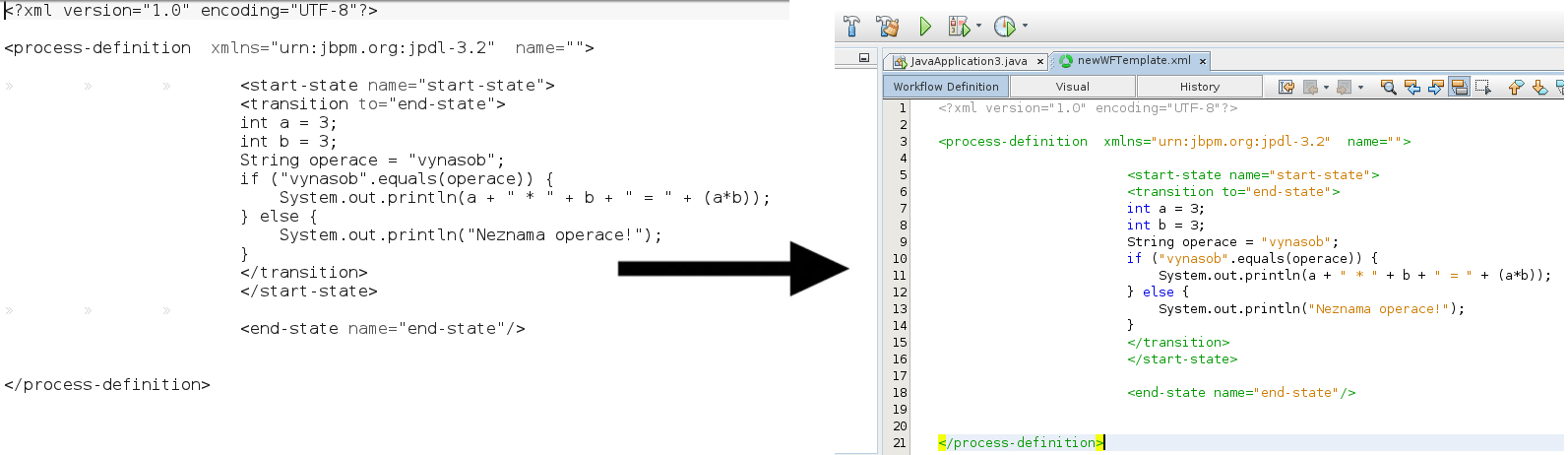
Lexer
Slovem „lexer“ se rozumí program (ve světě Javy třída), který čte text nějakého jazyka a na základě dané gramatiky chápe jeho formální význam. Lexer přečte zdrojový kód, rozseká ho na tokeny a ke každém tokenu vývojovému prostředí sdělí typ. Jenom díky lexeru pro Javu Netbeans vědí, že „while“ mají zbarvit dofialova, kdežto řetězec oranžově. S pojmem „lexer“ je příbuzný pojem „parser“. Parser je ovšem něco víc, parser vyhodnocuje jednotlivé tokeny i v kontextu celého kódu.
Lexer: „Narazil jsem na token readFile. To vypadá jako identifikátor metody.“
Parser: „Narazil jsem na token readFile. To vypadá jako identifikátor metody. Znám takovou metodu? Existuje na třídě? Kolik má mít parametrů? Odpovídají jejich typy těm, které se tam programátor snaží dosadit? …“
Jak na to…
Jak vytvořit nový lexer pro určitý typ souboru do Netbeans?
1. Vytvořit projekt pro nový modul (File – New Project – Netbeans Modules – Module)
2. Vytvořit podporu pro nový typ souboru (New – File Type). Nový typ můžete definovat buď pomocí jeho přípony, anebo podle kořenového elementu, pokud se jedná o XML soubor.
3. Vytvořit novou třídu reprezentující jazyk – nezapomeňte na anotaci @LanguageRegistration(mimeType = „text/wf“). Díky ní Netbeans začnou chápat třídu jako definici jazyka.
import eu.bcvsolutions.wfparser.WFParser;
import org.netbeans.api.lexer.Language;
import org.netbeans.modules.csl.spi.DefaultLanguageConfig;
import org.netbeans.modules.csl.spi.LanguageRegistration;
import org.netbeans.modules.parsing.spi.Parser;
@LanguageRegistration(mimeType = "text/wf")
public class WFLanguage extends DefaultLanguageConfig {
@Override
public Language getLexerLanguage() {
return WFTokenId.getLanguage();
}
@Override
public String getDisplayName() {
return "Workflow Definition";
}
@Override
public Parser getParser() {
return new WFParser();
}
}
4. Vytvořit třídu pro lexer. Lexer dostane na vstupu stream, ze kterého může číst znaky. Jeho jediným úkolem je znaky číst a vždy po určité sekvenci vrátit typ dalšího přečteného tokenu.
5. Vytvořit třídu reprezentující hierarchii jazyka – tahle třída se postará o to, aby jednotlivým typům tokenů, které bude lexer dodávat, někdo přiřadil „typ vzhledu“. Když tedy lexer řekne „Posledních 5 znaků jsou while“, odpoví hierarchie „while je klíčové slovo“.
import bsh.ParserConstants;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.Collection;
import java.util.HashMap;
import java.util.List;
import org.netbeans.spi.lexer.LanguageHierarchy;
import java.util.Map;
import javax.xml.stream.XMLStreamConstants;
import org.netbeans.spi.lexer.Lexer;
import org.netbeans.spi.lexer.LexerRestartInfo;
/**
*
* @author matochav
*/
public class WFLanguageHierarchy extends LanguageHierarchy<WFTokenId> {
private static List<WFTokenId> tokens;
private static Map<Integer, WFTokenId> idToToken;
public static int XML_TOKEN_OFFSET = 4000;
public static int XML_ATTR_VALUE = 134;
public static int XML_ELEMENT = 135;
public static int BSH_ERROR = 136;
private static void init() {
WFTokenId[] tokenArray = new WFTokenId[] {
new WFTokenId("EOF", "whitespace", 0),
new WFTokenId("NONPRINTABLE", "whitespace", 6),
new WFTokenId("SINGLE_LINE_COMMENT", "comment", 7),
new WFTokenId("HASH_BANG_COMMENT", "comment", 8),
new WFTokenId("MULTI_LINE_COMMENT", "comment", 9),
new WFTokenId("ABSTRACT", "keyword", 10),
new WFTokenId("BOOLEAN", "keyword", 11), ...
6. Vytvořit soubor FontAndColors.xml, ve kterém specifikujete, jak má být který typ vzhledu skutečně zobrazen. Až se tedy Netbeans od hierarchie dozví, že „while je klíčové slovo“, přečtou si ve FontAndColors.xml, že klíčová slova se píší fialově fontem Arial.
<!DOCTYPE fontscolors PUBLIC
"-//NetBeans//DTD Editor Fonts and Colors settings 1.1//EN"
"http://www.netbeans.org/dtds/EditorFontsColors-1_1.dtd">
<fontscolors>
<fontcolor name="character" default="char"/>
<fontcolor name="xml" default="field"/>
<fontcolor name="XML_DTD" default="char"/>
<fontcolor name="errors" default="error"/>
<fontcolor name="identifier" default="identifier"/>
<fontcolor name="keyword" default="keyword" />
<fontcolor name="literal" default="literal" />
<fontcolor name="comment" default="comment"/>
<fontcolor name="number" default="number"/>
<fontcolor name="operator" default="operator"/>
<fontcolor name="string" default="string"/>
<fontcolor name="separator" default="separator"/>
<fontcolor name="whitespace" default="whitespace"/>
<fontcolor name="method-declaration" default="method">
<font style="bold" />
</fontcolor>
</fontscolors>
Detekce chyb
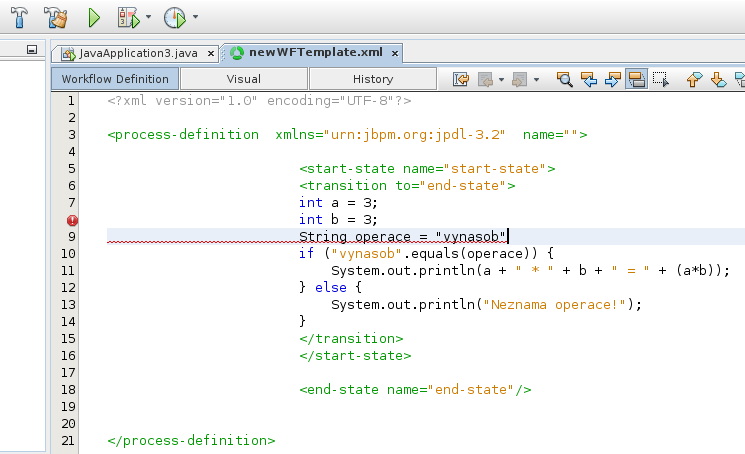
Když uděláte svůj lexer šikovně, pomůže vám rovnou detekovat některé základní syntaktické chyby, třeba chybějící středníky:
Závěr
V článku jste se mohli dozvědět, co je to lexer a jak vytvořit nový lexer pro platformu Netbeans. Mám v plánu do svého rozpracovaného modulu přidat mnohem víc: zvýraznění sémantických chyb, automatické doplňování kódu, zvýrazňování párů závorek, upload workflow na aplikační server přímo z Netbeans a ještě spoustu dalšího. Držte mi palce a kdybyste se chtěli na něco zeptat, napište na vojtech.matocha@bcvsolutions.eu. Všechny komentáře jsou vítány!