Brand New CSV Connector

Do you have HR system that exports data into CSV or XLS file? You can try our brand new CSVConnConnector and easily transfer data into CzechIdM! This connector was developed for easy synchronization of CSV files into our system. The connector is mostly for synchronization. Provisioning methods (update, create, delete) are implemented too but are not advised to be used now.
Improvements of the new connector
- The main point of creating new CSV connector was to be able to easily import data into CzechIdM
- Make the implementation easy, so that it is not dependent on other tools like database.
- We can easily improve implementation of the connector.
The connector is mostly used for synchronization. We are using ConnId framework which is used for most of our connectors. Now I prepared a little tutorial to follow. It can show how to load data into CzechIdM from CSV file.
Dependency to CzechIdm
First of all, you have to enable CSV connector in CzechIdM
Import .jar file into CzechIdM library
1) Please, download this to your computer.
2) Then copy it to YourServer(tomcat)/webapps/idm/WEB-INF/lib
3) We are now ready to do next steps.
Creating a new system
Now we have to move back to CzechIdM. First of all, we need to go to Systems and here Add new system.
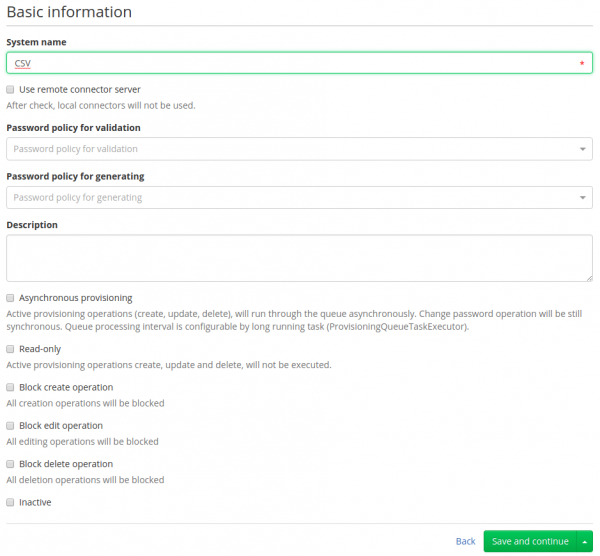
We need to fill name. Other options such as Password policies, Description or Checkboxes below are not mandatory. All information about these items is shown in the description of each.
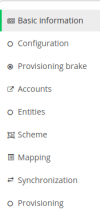
After saving the previous page we can reach this menu on the left side.
Configuration
Now we can reach Configuration page, where we need to set all properties for our CSV file. Look at the picture below:
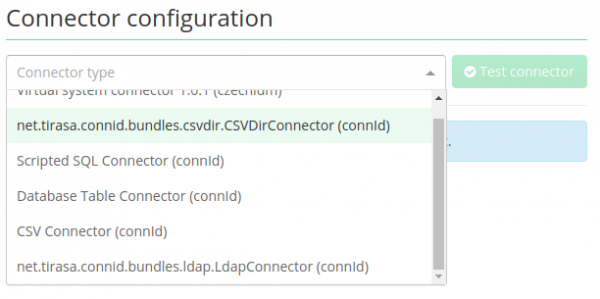
First, we need to set our CSV Connector (connId), then all other needed information will pop up. Follow the instructions on each property.
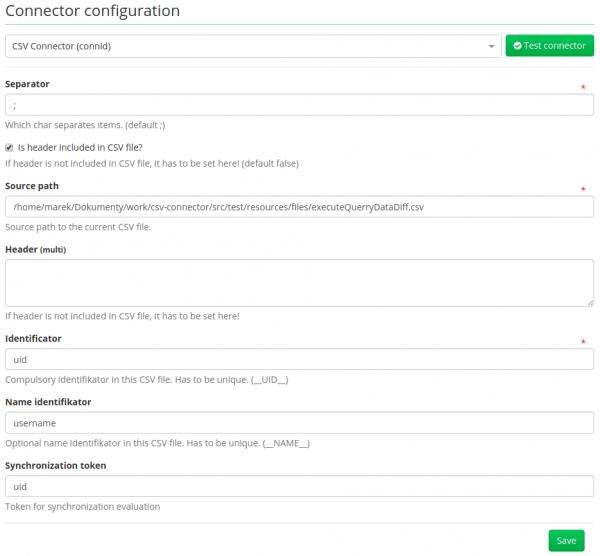
-
Separator – character between two different columns
-
Source path – path to the CSV file, which needs to be imported
-
Checkbox included – if the first line of CSV file includes the header
-
Header – if the file doesn’t include the header, we need to write the header here
-
Identifier – Which column holds the identifier
-
Name identificator – Which column holds the NAME
-
Synchronization token – token for repeated synchronization (not reconciliation)
After we filled all information needed, just click save and Test connector and see if everything went all right. If some exception pops up, follow the instruction given. If you are following my example just fill every single item same as shown in the picture.
Scheme
The most basic operation is Scheme. We just click generate schema and then our schema should pop already created at the bottom of this page.
1) Click on Generate schema

2) The schema should be created below for needed object (in our example case it is account)
3) Select the loop and the following page will pop up
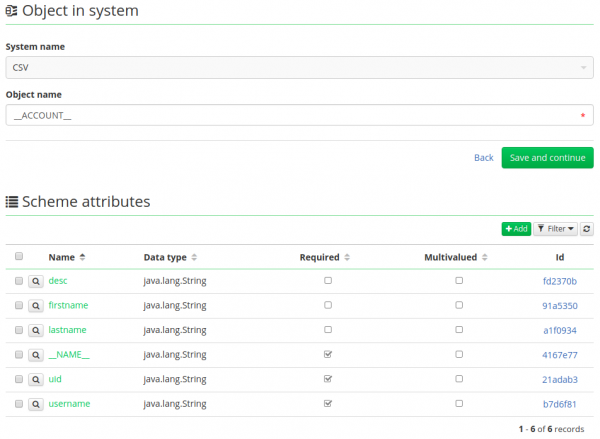
4) You can see that all items from our header were created as attributes here (desc, firstname, lastname…). You wonder what does the NAME stands for? In the configuration window, there is option Name, which is exactly what the NAME is (again in our example case it is username).
5) Please check if every single item from your header is present and then continue with next steps in this tutorial.
Mapping
We have our schema created but now we need to map all items in the schema to actual attributes in CzechIdM. 1) Fill all needed attributes according to this picture if you follow my example.
1) Fill all needed attributes according to this picture if you follow my example.
-
Operation type – type of operation. Synchronization for input data into CzechIdM and Provisioning for writing data into our CSV file (example.csv).
-
Mapping name – the name which will be then used in synchronization/provisioning according to operation type.
-
Object name – currently we have just account
-
Entity type – Type of entity which will be created – can be Identity (our example), Tree, Role and so on. Look at the list given for other.
2) Click Save and continue. 3) Now the blank table is shown at the bottom of this page. There is option add so we click on that.
3) Now the blank table is shown at the bottom of this page. There is option add so we click on that. 4) Attribute mapping detail – this is the page where you chose the item from the schema and actually map it to the attribute in CzechIdM. First, find Attribute in schema in the table of options for this select box. Name following will be set automatically. Warning: if we change our mind and set Attribute in schema to different option later, it won’t change name automatically.
4) Attribute mapping detail – this is the page where you chose the item from the schema and actually map it to the attribute in CzechIdM. First, find Attribute in schema in the table of options for this select box. Name following will be set automatically. Warning: if we change our mind and set Attribute in schema to different option later, it won’t change name automatically.
5) Attribute in CzechIdM and checkboxes with other info about attribute. 6) Fill all select boxes as shown in the pictures. We won’t use transformations so according to the last picture we leave these two boxes blank.
6) Fill all select boxes as shown in the pictures. We won’t use transformations so according to the last picture we leave these two boxes blank.
 7) Make sure you mapped all attributes you need – the table should look like this.
7) Make sure you mapped all attributes you need – the table should look like this.
For our example, we chose one of the items – lastname. All other items will be similar. Just for uid we need to choose select box Identifier and Extended attribute. Then just type to IdM key – uid.
If you want to know more about this topic, there is also the whole tutorial on mapping attributes in this LINK.
Synchronization
It starts with the addition of new synchronization.
First Reconciliation
In this part, we never put this example.csv in the system yet. So we have to put all data inside.
1) We just simply have to set Allowed and Reconciliation – first, attribute only says that it can be run and second says that no filter is given.
2) Choose your Name and Set of mapped attributes you created in previous steps.
3) Correlation attribute is the attribute which should connect both attribute in CzechIdM and item in the example.csv. 4) There are more options but in this case, we won’t change anything. For a brief explanation of what to set here follow this LINK.
4) There are more options but in this case, we won’t change anything. For a brief explanation of what to set here follow this LINK.
5) After save and continue we can run our Synchronization.
See the log
If we want to make sure that our Identities were made, we can look into our identities or we can look into the log of our Synchronization.
1) Click on the Loop and then at the top of the page find Logs and follow to this page.
2) Now result should say: „Some number“ Created Entities as shown in the picture (we created 11 identities).
3) We can go further and finds out which identities were created. Just click again on the Loop. 4) You will see the log in the top part of the page but we will look at the bottom as picture shows. There click on the Loop.
4) You will see the log in the top part of the page but we will look at the bottom as picture shows. There click on the Loop. 5) Now you should see same as is shown in the picture.
5) Now you should see same as is shown in the picture.
I hope you like this article and for more information about our bright new connector feel free to contact me at email address: info@bcvsolutions.eu.