Oracle Waveset: připojujeme systém pomocí Scripted JDBC adaptéru
Značný počet systémů, které jsou používané v dnešní době, ukládá data o svých uživatelích do relační databáze. Každá databáze má ale jinou strukturu; data jsou rozložena do různých tabulek a má se s nimi v různých situacích jinak zacházet – některé systémy například mažou informace o odstraněných uživatelích, některé ne. Scripted JDBC adaptér představuje univerzální řešení, jak podobné systémy napojit na identity manager Oracle Waveset. Neměnná kostra adaptéru je obalena několika skripty v jazyce BeanShell, v nichž jsou popsány akce specifické pro konkrétní systém. V článku vyložíme podrobný postup jak skripty napsat a jak systém nakonfigurovat v administrátorském rozhraní.

Oracle Waveset
Oracle Waveset je nástroj pro centrální správu identit, který společnost Oracle vyvíjí na základě původního Sun Identity Manageru. Identity manager zajišťuje přehledný, bezpečný a především plně automatický přenos dat o uživatelích mezi koncovými systémy: s novým záznamem v personálním systému tak mohou být založeny účty v operačních systémech, v Active Directory nebo mu mohou být přiřazena práva na konkrétní adresáře v adresářové struktuře. To vše bez ručního zásahu administrátora.
Nový koncový systém napojený přes JDBC
Náš zákazník si přál napojit systém postavený nad relační databází, říkejme mu třeba Systém. Identity manager měl v Systému spravovat role a oprávnění: každou roli v Systému tak bylo zapotřebí mapovat na roli v Identity manageru. Přiřazení role v Identity manageru mělo znamenat automatické přiřazení příslušné role v koncovém systému. Pro komunikaci jsme se rozhodli použít univerzální Scripted JDBC adaptér, který umožní přistupovat k relační databázi v jazyce Java obvyklým způsobem: pomocí standardních knihoven JDBC.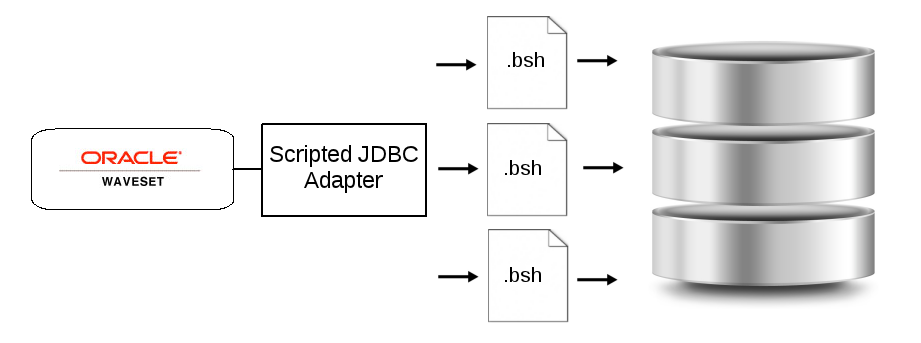
Spolupráce se zákazníkem
Identity manager může prostřednictvím skriptů přistupovat k libovolné tabulce nebo libovolnému pohledu v připojené relační databázi. Nám se ve fázi plánování osvědčila detailní konzultace se zákazníkem a pomoc z jeho strany: administrátor Systému pro naše účely vytvořil jednoduchý balíček několika databázových procedur, kterými budeme ze skriptů do Systému zasahovat. Výhod je několik: vytvořené skripty jsou přehlednější, a tedy méně náchylné k chybám, ale především nemusí být skripty měněny, kdyby došlo ke změně struktury v Systému, například migrací na novou verzi. Identity Manager pak přistupuje k databázi prostřednictvím neměnného rozhraní, například prostřednictvím balíčku:
create or replace package USER.PACKAGE as function createUser( pUserId varchar2, pUserName varchar2, pEmail varchar2); -- vytvoreni noveho uzivatele function deleteUser( pUserId varchar2); -- smazani uzivatele function updateUser( pUserId varchar2, pUserName varchar2, pEmail varchar2); -- aktualizace uzivatele function test () return char; -- test komunikace -- vraci: -- 'T' = bez chyb -- 'F' = nastala chyba function getUser ( pUserId varchar2, pRoleList out varchar2); -- seznam roli daneho uzivatele na koncovem systemu -- parametry: -- pRoleList = vystupni parametr: aktualni role na koncovem systemu function listAllUsers(pUserList out varchar2); -- aktualni seznam uzivatelu na koncovem systemu -- pUserList = vystupni parametr; aktualni uzivatele na koncovem systemu
Akce na Systému
Působení Identity Manageru na koncovém systému lze rozdělit do několika akcí: Jak mají být uživatelé vytvářeni? Jak se mají propagovat změny z Identity Manageru do Systému? Jak mají být uživatelé mazáni? Kteří uživatelé mají v Systému účet? Každé jednotlivé odpovědi na některou z předchozích otázek odpovídá jeden skript v jazyce BeanShell; v něm je zachycena logika zásahu do Systému.
- akce „getUser“ – vrací atributy daného uživatele
- akce „listAllUsers“ – vrací seznam identifikátorů uživatelských účtů na koncovém systému
- akce „updateUser“ – aktualizuje atributy na koncovém systému podle atributů v Identity Manageru
- akce „createUser“ – založí nový účet se stanoveným identifikátorem a zadanými atributy
- akce „deleteUser“ – odstraní účet s daným identifikátorem
- akce „disableUser“ – zneplatní uživatelský účet s daným identifikátorem
- akce „enableUser“ – aktivuje uživatelský účet s daným identifikátorem
- akce „test“ – otestuje spojení s koncovým systémem
- …
Výše uvedený seznam obsahuje jen základní akce, které bývají obvykle implementovány. Obecně platí, že některé akce implementovány být nemusí – v takovém případě Identity Manager příslušné akce na koncovém systému neumožňuje. Oracle Waveset umožňuje definovat další, pokročilé akce, například pro efektivní synchronizaci a rekonciliaci.
Skripty
Každé akci na Systému odpovídá jeden skript. Podobně jako všechny objekty, s nimiž Oracle Waveset pracuje, jsou i tyto skripty zachyceny v XML struktuře, podporovanými jazyky jsou v současnosti BeanShell a JavaScript.
Skripty, které využívá JDBC adaptér, přistupují do databáze pomocí obvyklých JDBC tříd v jazyce Java. Každý skript tak dostane na vstupu instanci třídy Connection, která představuje spojení na databázi koncového systému. Vstupní atributy se dále liší podle konkrétní akce: update uživatele například dostane na vstupu hodnoty atributů.
Podívejme se zblízka na skript, který na Systému zakládá nové uživatelské účty:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE ResourceAction PUBLIC 'waveset.dtd' 'waveset.dtd'>
<ResourceAction name='createUser-bsh'>
<ResTypeAction restype='ScriptedJDBC' actionType='BeanShell'>
<act>
import java.sql.*;
Connection conn = actionContext.get("conn");
List resultList = actionContext.get("resultList");
List errors = actionContext.get("errors");
String id = actionContext.get("id");
Map attributes = actionContext.get("attributes");
CallableStatement stmnt = null;
try {
stmnt = conn.prepareCall("{call USER.PACKAGE.createUser(?, ?, ?)}");
stmnt.setString(1, id);
stmnt.setString(2, attributes.get("name"));
stmnt.setString(3, attributes.get("email"));
stmnt.executeQuery();
} catch (Exception e) {
errors.add(e.getMessage());
} finaly {
if (stmnt != null) {
stmnt.close();
}
}
</act>
</ResTypeAction>
</ResourceAction>
Kořenovým elementem xml je tag „ResourceAction“, v atributu „name“ stanovíme název skriptu. V typu akce poté specifikujeme, že se jedná o akci pro Scripted JDBC adaptér a že půjde o skript napsaný v BeanShellu (druhou možností by byl JavaScript). V tagu „act“ se nachází samotné tělo skriptu. Na začátku skriptu získáme z „actionContext“ vstupní parametry: v parametru conn je spojení na databázi, výstupní seznam „errors“ je na začátku skriptu vždy prázdný, na konci obsahuje chybová hlášení. Parametr „id“ stanovuje identifikátor, pod nímž bude k účtu po vytvoření přistupováno. Mapa „attributes“ nakonec drží všechny atributy pro koncový systém, v našem příkladu jsou to atributy „name“ a „email“.
Administrátorské rozhraní
Jakmile jsou skripty dokončeny – jejich vývoj a testování je pro zkušeného programátora práce na několik málo dnů. Zbývá systém správně nakonfigurovat přes administrátorské rozhraní. Dále si ukážeme podrobnější postup.
1. v okně výše klikneme na „Resource Type Actions“ a vybereme možnost „New Resource“.
2. V nabídce zvolíme typ koncového systému „ScriptedJDBC“ a potvrdíme kliknutím na „New“.
3. Objeví se okno průvodce pro připojení systému přes ScriptedJDBC. Klikneme na „Next“.
4. V následujícím formuláři vyplníme přístupové údaje k databázi. Kliknutím na „Test Configuration“ můžeme ověřit, zda jsou údaje platné a zda se spojení podařilo navázat. JDBC driver musí být mezi knihovnami, ke kterým má aplikace přístup.
 5. Na další stránce zvolíme pro jednotlivé akce příslušné skripty. Je možné zvolit skriptů i více, v takovém případě se budou provádět v pořadí od svrchního po nejspodnější.
5. Na další stránce zvolíme pro jednotlivé akce příslušné skripty. Je možné zvolit skriptů i více, v takovém případě se budou provádět v pořadí od svrchního po nejspodnější.
6. Nyní musíme namapovat atributy v Identity Manageru na atributy koncového systému. Na obrázku níže vidíme, že hodnota atributu „name“ v Identity Manageru bude do skriptů provádějících akce na koncovém systému předána pod názvem „fullName“.

7. V dalším kroku určíme, jak budou identifikovány účty na koncovém systému. V příkladu níže uvádíme, že identifikátor na koncovém systému bude stejný jako identifikátor účtu v Identity Manageru.

8. Posledním krokem je zvolení názvu koncového systému a nastavení některých pokročilejších konfigurací – některé akce můžeme pro koncový systém deaktivovat a stanovit, jak se má Identity Manager zachovat, pokud k takové deaktivované akci dojde; zda má zahlásit chybu, nebo akci zcela ignorovat.
Závěr
V článku jsme si ukázali, jak jednoduché může být propojení Identity Manageru a systému, který běží nad komplikovanou strukturou tabulek v relační databázi. Kdybyste měli ohledně článku nebo našich práce související s centralizovanou správou identit jakýkoli dotaz, můžete se na mě obrátit na mojí e-mailové adrese vojtech.matocha@bcvsolutions.eu!