Oracle: paralelní zpracování
Dnešní databáze běžně obsahují miliony záznamů. Kdyby je měl databázový stroj při každé změně či každém dotazu procházet postupně jeden po druhém, trvalo by to několik hodin. Řešením, které vytěží maximum z dostupného hardware a zvládne úkol v mnohem kratším čase, může být paralelizace. Databáze Oracle verze 11 tuto možnost poskytuje. V článku se podíváme, jak si z pozice administrátora paralelní zpracování na některých databázových objektech vynutit, anebo naopak zakázat, a ukážeme si některé zajímavé parametry, které s paralelizací souvisejí.
Přístup k datům
V zásadě existují dva přístupy, jak z pozice databázového stroje nakládat s daty. První, nazývaný „shared nothing“ předpokládá pevné rozdělení dat do samostatných oddílů
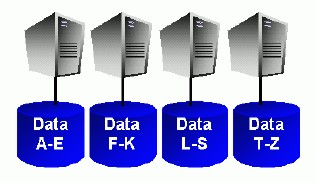
Shared nothing
Nad každým oddílem může pracovat jeden proces, aniž by jakkoli konkuroval procesům, které pracují nad ostatními oddíly. Databáze Oracle tento způsob nepoužívá. Princip „shared nothing“ totiž není flexibilní a nedokáže se přizpůsobit nenáhodným datům: pokud by všechna data v našem příkladu spadala například do skupiny „A-E“, paralelizaci by to de facto znemožnilo.
Oracle proto preferuje přístup „shared everything“:
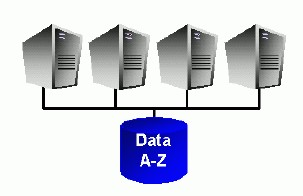
Shared everything
Všechna data jsou pohromadě a postup paralelizace se odvíjí od aktuálního stavu databáze: od velikostí konkrétních tabulek, od existujících indexů nebo od počtu procesů, které jsou v danou chvíli k dispozici. To je samozřejmě nákladnější na synchronizaci procesů, zaručuje to však postup „na míru“ aktuálním datům a ve výsledku dosahuje lepších výsledků.
Plán provedení dotazu
Před provedením každého dotazu Oracle nejprve sestaví plán, jak bude postupovat. Tento plán se odvíjí od aktuálního stavu databáze. Administrátor si může plán prohlédnout pomocí následujících příkazů:
EXPLAIN PLAN FOR SELECT name FROM employee;
Tento příkaz neprovede zadaný dotaz „SELECT name FROM employee“, pouze vytvoří plán zpracování a uloží jej do globální dočasné tabulky PLAN_TABLE. Z ní lze potom vyčíst všechny důležité informace: jednotlivé kroky zpracování, s kolika řádky bude který krok pracovat, nakolik pravděpodobně vytíží procesor nebo kolik bude vyžadovat paměti. Nejdůležitější informace o posledním přidaném plánu lze zobrazit příkazem:
SELECT * FROM TABLE(dbms_xplan.display());
Výsledkem příkazu mohou být například následující řádky:

Plán query
Koordinátor dotazu a dílčí procesy
Dotaz uživatele je přijat jedním procesem. Ten má na starost provedení celého dotazu a stává se tedy jeho „koordinátorem“ (anglicky „Query Coordinator“). Sestaví plán a na jeho základě povolá pro dílčí úkoly další procesy, které jsou v daném okamžiku k dispozici v zásobě (server process pool). Ty vykonají své dílčí úkoly paralelně, čímž mohou výrazně zkrátit dobu běhu. Například v operačním systému Linux bývají tyto procesy odlišitelné od ostatních prefixem „ora_p“. Celkový počet procesů zapojených do výkonu jednoho dotazu se nazývá stupeň paralelizace, anglicky „Degree of parallelism“ (DOP).
Jak zajistit paralelizaci?
Zda se dotaz bude, či nebude vykonávat paralelně (a jaký bude případně DOP), zajišťuje defaultně sama databáze. Administrátor má však možnost automatické vyhodnocování potlačit a zajistit paralelizaci ručně. Pro jednu tabulku to může učinit příkazem
ALTER TABLE employee PARALLEL 4;
Celé číslo na konci příkazu udává DOP pro danou tabulku.
Podobně je možné vynutit paralelizaci své session příkazem
ALTER SESSION FORCE PARALLEL QUERY;
nebo doporučit paralelní zpracování pomocí takzvaného „hintu“ pro jednu konkrétní query:
SELECT /*+PARALLEL(emp 4)*/ name FROM employee emp;
Parametry databáze Oracle
Databázi Oracle je možné konfigurovat pomocí parametrů, které jsou uloženy v souboru init.ora. V poslední verzi jich je přibližně 900, my se budeme zabývat pouze těmi, které souvisejí s paralelizací. Zobrazení současné hodnoty parametru je možné dvěma způsoby. Jednak příkazem
SHOW PARAMETERS jmenoParametru;
který vypíše všechny parametry, jejichž názvy obsahují zadaný řetězec; jednak přímým dotazem do pohledu V$PARAMETER:
SELECT * FROM V$PARAMETER WHERE name = 'jmenoParametru'.
Přenastavení parametrů je potom možné příkazem
ALTER SYSTEM SET jmenoParametru=hodnotaParametru;
Přehled parametrů ovlivňujících parametry
Na závěr se podíváme na některé důležité parametry, kterými lze konfigurovat paralelní zpracování. Vypsat všechy takové parametry i s jejich hodnotami je snadné pomocí příkazu SHOW, všechny totiž začínají společným prefixem PARALLEL_.
PARALLEL_DEGREE_POLICY
Určuje, zda bude paralelizace určována automaticky (možnost AUTO) nebo ručně (MANUAL).
PARALLEL_MIN_SERVERS
Počet procesů, které jsou spuštěny při startu databáze, sloužících k provádění paralelních úkonů.
PARALLEL_MAX_SERVERS
Tento klíčový parametr stanovuje maximální počet procesů zabývajících se paralelním zpracováním, které mohou zároveň běžet na jedné instanci databáze. Zvýšení tohoto parametru může významně urychlit některé dotazy, na druhou stranu to s sebou přináší i jisté riziko: každý proces vyžaduje jisté nezanedbatelné množství paměti, která může pro příliš vysoké hodnoty scházet.
PARALLEL_THREADS_PER_CPU
Počet paralelních vláken běžících na jednom jádru. Obecně bývá nastaven na hodnotu 2 a nemá smysl ho měnit.
PARALLEL_EXECUTION_MESSAGE_SIZE
Některé paralelní procesy jsou ve vztahu „producent – konzument“. Tento parametr slouží ke stanovení velikosti bufferu v paměti, kterým si předávají zprávy. Navýšení tohoto bufferu může výrazně urychlit některé query.
PARALLEL_DEGREE_LIMIT
Celé číslo určující maximální DOP, má-li být nastavován automaticky. Defaultně je odvozen jako CPU_COUNT X PARALLEL_THREADS_PER_CPU X ACTIVE_INSTANCES, tedy z počtu dostupných jader a stanoveného počtu vláken, které smí běžet na jednom jádru.
Závěr
V tomto článku jsme se seznámili s principem paralelního zpracování query na databázi Oracle 11 a s některými důležitými parametry. Kdybyste měli k článku jakýkoli dotaz, neváhejte se ptát na adrese vojtech.matocha@bcvsolutions.eu!