Hibernate: cizí klíče bez cizích klíčů
Při implementaci našeho Identity Manageru CzechIdM jsme narazili na zajímavý problém týkající se technologie Hibernate a struktury tabulek v databázi. Potřebovali jsme zajistit funkcionalitu, kterou běžně poskytují v databázi cizí klíče. Jenže právě cizí klíče jsme použít nemohli. V tomto článku se na náš problém podíváme a vysvětlíme si, jak se nám ho podařilo vyřešit s použitím některých pokročilejších Hibernate anotací.
Jak používáme Hibernate?
Hibernate je framework v jazyce Java, umožňující objektově-relační mapování. Běžný Java objekt lze pomocí Hibernate mapovat na jeden řádek tabulky v databázi. V našem CzechIdM používáme Hibernate pro uskladnění informací o nejrůznějších entitách – uživatelích, rolích, organizacích a mnoha dalších. Každá taková entita je běžnou Java třídou s příslušnými Hibernate anotacemi:
@Entity
@Table(name = "roles")
public class Role implements Serializable {
...
}
@Entity
@Table(name = "identities")
public class Identity implements Serializable {
...
}
@Entity
@Table(name = "organizations")
public class Organization implements Serializable {
...
}
Anotací @Entity musí být označena každá ukládaná entita, anotací @Table říkáme, jak se má jmenovat tabulka, do které se bude daná entita ukládat.
Tabulky
Každá naše entita je v databázi ve své vlastní tabulce a každá v ní používá svůj vlastní primární klíč. Například pro roli je primární klíč přímo jejím názvem, kdežto pro uživatele může být primární klíč automaticky generován z křestního jména a příjmení.
Zavádíme „extended“ atributy
Do našeho CzechIdM bychom rádi implementovali takzvané „extended“ atributy. Ty obsahují nějakou doplňující informaci o dané entitě: pro uživatele to může být datum začátku pracovního poměru nebo seznam titulů, pro organizaci třeba seznam rolí, které má každý její člen automaticky získat. Rádi bychom tedy zavedli novou entitu realizovanou třídou ExtendedAttribute se vztahem N:1 k ostatním entitám. Jedna konkrétní entita může mít žádný nebo více svých extended atributů, zatímco jeden konkrétní extended atribut náleží vždy právě jedné entitě.

Jak smazat entitu i s jejími extended atributy?
Problém, na který narážíme, vypadá na první pohled velmi jednoduše: jak docílit toho, aby byly spolu s entitou automaticky smazány z databáze i všechny její extended atributy? Odstraníme-li z databáze organizaci, chceme s ní automaticky odstranit i všechny její členy a s nimi i všechny jejich extended atributy. Jak na to?
Řešení na úrovni databáze?
Na úrovni databáze lze takový problém obvykle vyřešit pomocí cizích klíčů – jeden ze sloupců tabulky extended atributů by byl primárním klíčem entity, k níž atribut patří. Jenže: primární klíče v naší databázi nejsou unikátní napříč tabulkami – identita se může jmenovat stejně jako role nebo organizace. Jak tedy poznat, do které tabulky konkrétní cizí klíč ukazuje? Na úrovni databáze žádné elegantní řešení neexistuje, musíme o stupínek výš – na úroveň Hibernate.
Řešení na úrovni Hibernate!
Společný předek
Prvním krokem, který musíme učinit, je zavedení jednotného identifikátoru napříč všemi entitami. Ten se nestane primárním klíčem v jednotlivých tabulkách – změna primárního klíče je komplikovaná záležitost a znamenala by změny ve struktuře celé databáze. Za tímto účelem si vytvoříme společného předka všech entit v našem CzechIdM. Na něm zadefinujeme náš nový jednoznačný identifikátor, pomocí něhož budeme určovat vlastnictví extended atributů.
@MappedSuperclass
public class IdmEntity {
@Column
private String entityId;
...
}
@Entity
@Table(name = "roles")
public class Role extends IdmEntity implements Serializable {
...
}
@Entity
@Table(name = "identities")
public class Identity extends IdmEntity implements Serializable {
...
}
@Entity
@Table(name = "organizations")
public class Organization extends IdmEntity implements Serializable {
...
}
Anotace @MappedSuperclass říká, že třída IdmEntity není sama entitou ukládanou do databáze, pouze definuje některé vlastnosti, které mají mít všichni její potomci: identity, organizace, role… Jednou z těchto vlastností je právě unikátní identifikátor entityId. Ten je ve třídě označen anotací @Column, která říká, že atribut entityId má být ukládán do databáze pro každého potomka třídy IdmEntity.
Vztah s extended atributy
Na úrovni Hibernate lze vztah 1:N nastavit pomocí anotace @OneToMany u příslušného atributu, který je typu kolekce. Pomocí této anotace můžeme nastavit, jak se mají události na entitě (například smazání) projevit na extended atributech. My bychom chtěli, aby se extended atributy mazaly spolu s entitou, zvolíme tedy možnost cascade = CascadeType.All. Podívejme se, jak se změnil kód naší třídy:
@MappedSuperclass
public class IdmEntity {
@Column
protected String entityId;
@OneToMany(cascade = CascadeType.ALL)
private List<ExtendedAttribute> extendedAttributes = new ArrayList<ExtendedAttribute>();
...
}
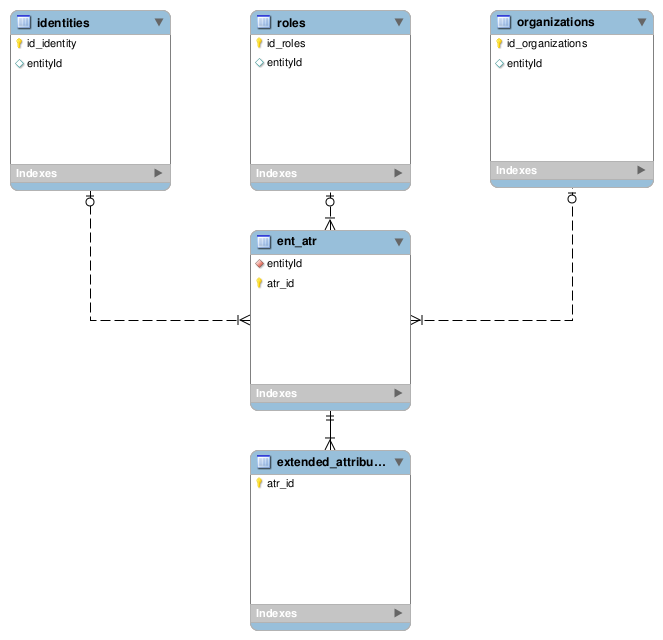
Spojovací tabulka
Mohlo by se zdát, že máme vyhráno, ale není tomu tak. Pokud mu neřekneme jinak, pokusí se Hibernate navázat vztah mezi entitou a jejími extended atributy obvyklým způsobem – pomocí cizích klíčů. A selže, protože se na každou entitu bude odkazovat pomocí jejího primárního klíče, který není napříč tabulkami unikátní. My mu musíme poradit, aby si vytvořil pomocnou tabulku ent_atr, ve které bude vztah definovaný pomocí našeho nového identifikátoru entityId. Ten je unikátní napříč tabulkami. K tomu nám poslouží anotace @JoinTable:
@MappedSuperclass
public class IdmEntity {
@Column
protected String entityId;
@OneToMany(cascade = CascadeType.ALL)
@JoinTable(name ="ent_atr", joinColumns = { @JoinColumn(referencedColumnName="entityId")},
inverseJoinColumns = {@JoinColumn(referencedColumnName="atributeId")})
private List<ExtendedAttribute> extendedAttributes;
...
}
Uvnitř anotace @JoinTable specifikujeme nastavením name název tabulky, která má vzniknout. Pomocí joinColumns a inverseJoinColumns zase uvádíme, pomocí kterých sloupců má být vztah 1:N zaveden. Přesvědčíme tak Hibernate, aby místo primárních klíčů používal náš nový identifikátor entityId. Hibernate za nás sám vytvoří schéma tabulek, které si můžeme prohlédnout na obrázku níže, a zajistí, aby byly změny propagovány podobně jako při použití cizích klíčů.
Poslední úkol
Zbývá poslední drobnost: zajistit, aby se před uložením každé entity vygeneroval jednoznačný identifikátor. Toho docílíme snadno pomocí anotace @PrePersist na třídě IdmEntity: takto označená metoda je vždy volána předtím, než je objekt poprvé uložen do databáze:
@MappedSuperclass
public class IdmEntity {
...
@PrePersist
private void generateEntityId() {
...
}
...
}
Závěr
V tomto článku jsme se seznámili s některými méně obvyklými anotacemi technologie Hibernate a podívali se, jak elegantně vyřešit náš problém. Pokud byste se nás chtěli zeptat na něco ohledně tohoto článku nebo našeho Identity Manageru CzechIdM, neváhejte mi napsat na vojtech.matocha@bcvsolutions.eu!